

 资讯(xùn)
资讯(xùn)3月16日(rì),百度正式发(fā)布(bù)大语(yǔ)言模型、生成式AI产(chǎn)品(pǐn)“文心一言”。百度创始人、董事长兼(jiān)首席执行官李彦宏及百度(dù)首(shǒu)席技术官王(wáng)海峰出席发布会。李(lǐ)彦宏展示(shì)了文心一言在(zài)文学创作、商业文案创作、数理推算、中文理解、多模(mó)态生成五个使(shǐ)用场景中的综合能力。
“生成(chéng)式AI代表(biǎo)着(zhe)新的技术范式(shì),是任何企业都不应错过的(de)大(dà)机(jī)会。”李彦宏说,“这段时(shí)间不断有人问我(wǒ),为什么现在发布,你们是不是真的ready了?其实,百(bǎi)度在过去(qù)十几年中持续在AI研发(fā)上(shàng)坚持(chí)投入,文心大模型(xíng)第一个版本2019年就发布(bù)了,此后的每一年(nián)都(dōu)发布一(yī)个新版(bǎn)本,从(cóng)这个意义上说(shuō),文心一(yī)言的发布只是我(wǒ)们过去多年努(nǔ)力(lì)的(de)一个(gè)自然延续。”
李彦宏表示,大家的(de)期望值(zhí)是要对标ChatGPT,甚至(zhì)要对标GPT-4,这个门槛(kǎn)还(hái)是很高(gāo)的。全球的(de)大厂当中,百(bǎi)度(dù)是(shì)第(dì)一个(gè)“发布”的。他说,内测中“文心(xīn)一言”并不完美,之所以现在要发布,原因在于(yú)市(shì)场有强烈需求。其定(dìng)位是通用(yòng)大模(mó)型。
李彦宏认为,多(duō)模态(tài)是生(shēng)成式AI一个明确的发展趋(qū)势。未(wèi)来,随着百度多模态统一大模型的能力增强,文心一(yī)言的(de)多模(mó)态生成(chéng)能(néng)力也会不断提升。而大模型会带来三(sān)大产业机会(huì):新型云(yún)计算、行业模型精调、应用开发(fā)。
发布会举行(háng)时(shí),截至14时(shí)22分(fèn),百度集(jí)团(09888.HK)股价跌幅(fú)扩(kuò)大(dà)至近(jìn)10%,报(bào)120.5港元/股(gǔ)。
演示(shì)五个场景下的能力(lì)
发布会(huì)上,百(bǎi)度播放了“文心一言”的演示视频,以(yǐ)下为演(yǎn)示实录。
文学创作
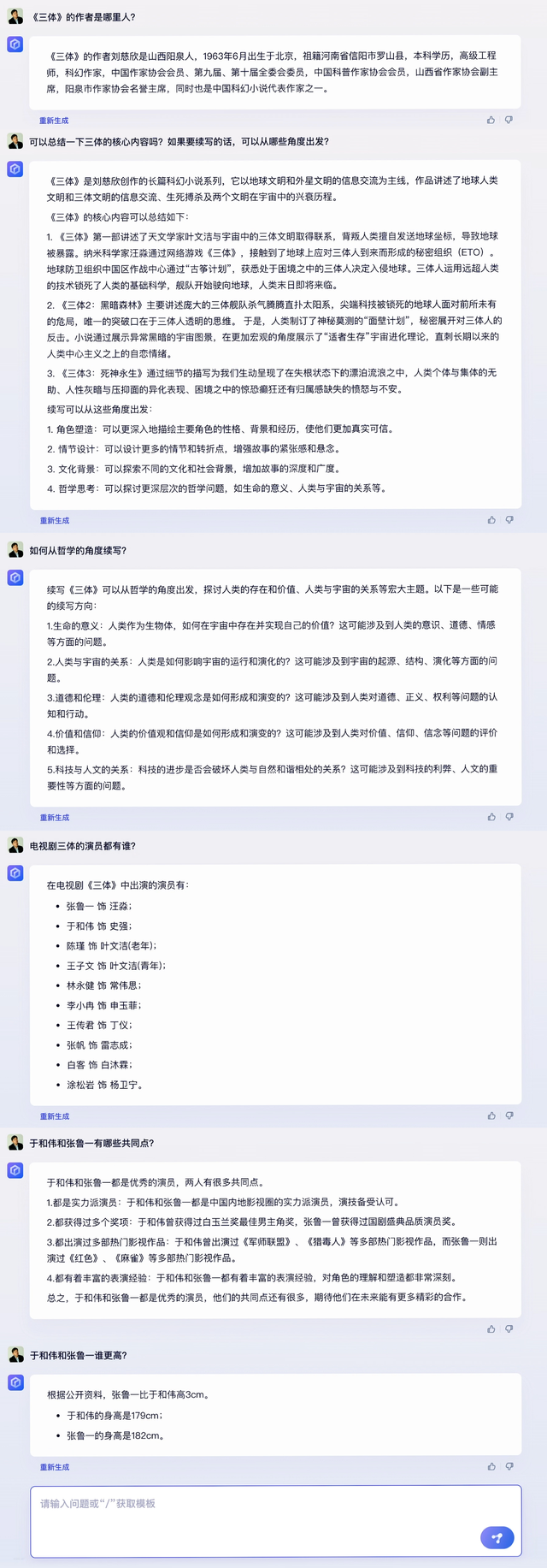
问题(tí):
· 《三体》的作者是哪里人(rén)?
· 可以总结一(yī)下《三体》的核心内容吗?如果要续写(xiě)的话,可以(yǐ)从哪些角度出发?
· 如何(hé)从哲学的角度续写(xiě)?
· 电视剧《三体》演员都有(yǒu)谁?
· 于和(hé)伟和张鲁一有哪(nǎ)些(xiē)共(gòng)同点?
· 于和(hé)伟和张鲁一谁更高?
李彦宏:刚(gāng)才的演示中,“总(zǒng)结三体的核心内容”,体现的(de)是文心一言的总(zǒng)结、分析(xī)能力。续写《三(sān)体》,体现的是内容(róng)创作生成能力。
《三体》的作(zuò)者是谁?他是哪里人?电视剧三体演员都有谁?文心(xīn)一言回(huí)答是正确的(de)。大家(jiā)可能知道(dào),生成式AI这(zhè)类产品,在回答事实性(xìng)问题(tí)时,有时候会出(chū)错。文心(xīn)一(yī)言延续了百度知识增强的(de)大模型理(lǐ)念,大幅度提升了事实性问题的(de)准确率。
于和伟和张鲁(lǔ)一有(yǒu)哪些(xiē)共同点(diǎn)、于和伟和张鲁(lǔ)一谁更高?这类问题(tí)背(bèi)后,则体现的是文心一言的推理(lǐ)能力。比如,它得先知道两(liǎng)人的准确身高,才能得出(chū)正确答案。
商业文案创作
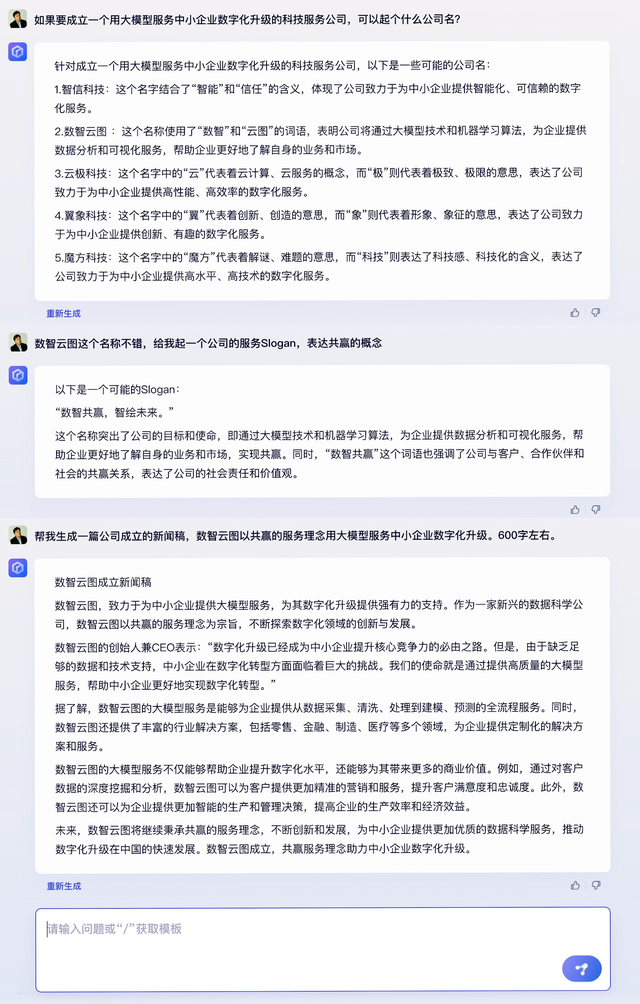
问(wèn)题:
· 如(rú)果(guǒ)要成立(lì)一个用大模(mó)型服务中(zhōng)小企业数字(zì)化升级的科技服(fú)务公(gōng)司,可以起个什么公司名?
· 数智云图这个名(míng)称不错,给(gěi)我起一个公司的服务(wù)Slogan,表达(dá)共(gòng)赢的概念(niàn)。
· 帮我生成一篇公司成立的新闻稿,数智云图以共赢的服务理念用(yòng)大模型服务中小企业数字化升级。字数600字。
李彦宏:刚才的(de)演示,展现了(le)文心(xīn)一言连续三次内容(róng)创作生(shēng)成。
AI要写好一篇(piān)稿子,除(chú)了(le)需要(yào)准确理(lǐ)解我们(men)的意图,还要(yào)有清晰的表达能力。
这背后有一(yī)个基础,就是庞大的数据规(guī)模。人(rén)类常说“读(dú)万卷书”,而AI可以说是(shì) “读书破千亿卷”。文(wén)心一言(yán)大模(mó)型(xíng)的训练数(shù)据就包括,万亿级网页数据,数十(shí)亿的搜索数据和图片数据,百(bǎi)亿级的语音日均调用数据,以及5500亿事实的知识图谱等,这让百度在中文语(yǔ)言的(de)处理上,能够处(chù)于独一无二的位置。
有研究表明,数据规模足(zú)够大,参数达(dá)到千亿级,大模型就可能(néng)发生“智(zhì)能涌现”,即使在没(méi)有专门训练过的领域,也能涌现出知识理解和(hé)逻辑推理能(néng)力(lì)。
数理逻辑推算(suàn)任务

问题(tí):
· 下(xià)面我们(men)来玩一(yī)个鸡兔同笼的游戏。1只鸡有2只脚(jiǎo)1个头,1只(zhī)兔子有4只脚1个头。那么,如(rú)果有一个笼子里(lǐ)有9个头,40只脚(jiǎo),应该有多少(shǎo)只鸡,多少只兔子?
· 下(xià)面我们来玩(wán)一个鸡兔同笼的游戏。1只(zhī)鸡有2只(zhī)脚1个头,1只兔子有4只脚1个头。那么,如果有一个(gè)笼子里有9个头,30只脚,应该有多(duō)少只鸡,多(duō)少(shǎo)只兔(tù)子?
李彦宏:对(duì)于第一(yī)道(dào)题(tí),文心一言经过演(yǎn)算,认为(wéi)可能是题出错了。对于第二道,文心一言不但给(gěi)出了正确结果,还(hái)详细给出(chū)解题步(bù)骤。可以(yǐ)看出(chū),文心一言能理解题意(yì),并有(yǒu)正(zhèng)确的解题思路,进而像学(xué)生(shēng)做题(tí)一(yī)样,按(àn)正确的步骤(zhòu),一步步算出正确答案(àn)。
文心一(yī)言已(yǐ)具备(bèi)了(le)一定的思(sī)维能力(lì),能够学会数学推演及(jí)逻辑(jí)推理这(zhè)类相对复杂任(rèn)务。当(dāng)然,现阶段准确率还不是100%,我们还需要给(gěi)它更多的时间来学习和成长。
中文理解能力

问(wèn)题(tí):
· “洛阳纸(zhǐ)贵(guì)”是什么意思?
· 当时(shí)洛(luò)阳(yáng)的纸到底(dǐ)有多贵?
· 这个成(chéng)语在现在的经济(jì)学原理里(lǐ),对应的(de)理(lǐ)论是什(shí)么?
· 用洛阳纸贵四个字写一首藏头诗。
李彦(yàn)宏:“洛阳纸贵”,“藏头诗”,这(zhè)很(hěn)考验AI对中(zhōng)文和中国文化的理解。
作为扎根于中国市场(chǎng)的大语(yǔ)言(yán)模型,文心一言具备中文领域最(zuì)先进的自然语言处(chù)理能力。这个例子就比较清楚地展示了(le)我们在(zài)中文上的优势。
相对应的,文心一言目前对英文语(yǔ)种、代(dài)码场景的训练还不(bú)够多,表现还不够好,接下来我们(men)还要(yào)加(jiā)紧训练,不(bú)断完善这些能(néng)力。
多模态生成

问(wèn)题:
· 请为2023世界智(zhì)能交(jiāo)通(tōng)大会创作一张海报(bào)。
· 你认为(wéi)智能交通最适合哪个城市发展?
· 请用四川话(huà)将以上内容(róng)讲出来(lái)。
· 请将(jiāng)以上(shàng)内容(róng)生成视频。
李彦(yàn)宏:刚才(cái)这一段演示,文(wén)心一言生成(chéng)了文本、图(tú)片、音频(pín)和视频,展示(shì)了(le)多模态(tài)生成能(néng)力。目(mù)前的版本(běn),已经能(néng)够(gòu)生成文字、图片和语音(yīn)。生成视(shì)频因为成本比较高,还没(méi)有对所有用户开(kāi)放(fàng),未来我们会逐步接入。但是熟悉百(bǎi)家号创(chuàng)作的朋友,应该都体验过这个功能了,每天有几(jǐ)万篇文章通过(guò)这个能力转成(chéng)视频内(nèi)容在百度分发。
多模态是(shì)生成式AI一(yī)个(gè)明(míng)确的发(fā)展趋势。未来,随着百度多模态统(tǒng)一(yī)大(dà)模型的能力增强,文心(xīn)一言的多模态(tài)生成(chéng)能力,也会不断提(tí)升(shēng)。
“四层架(jià)构的每一层都有领先产品”
在结束演示(shì)后,李彦宏总(zǒng)结道:“从(cóng)文心(xīn)一言的表(biǎo)现看,某种程度上(shàng)它具有了对人类(lèi)意图的理解能力,回答的准(zhǔn)确性、逻辑性(xìng)、流畅(chàng)性,都逐渐(jiàn)接近人类水平。但整体而言,这类大语言模(mó)型还(hái)远未到发展(zhǎn)完善的阶段,它们有时候会有很(hěn)惊艳的表(biǎo)现,但不少场景下,细究起来还有明(míng)显的bug,进步空间很大。未(wèi)来这段时间它一定(dìng)会(huì)飞速发展,日新(xīn)月异。”
李(lǐ)彦宏表示(shì),通(tōng)过定向(xiàng)微调,可以在百度内外(wài)部各类产品上逐(zhú)步展示出惊人(rén)的(de)亲和力(lì),让每(měi)一个产品离自(zì)己的(de)用户和客户更近。文心(xīn)一言这样(yàng)的(de)大语言(yán)模型,会(huì)成为每个人必不(bú)可少的生产力工(gōng)具。不过(guò),无(wú)论(lùn)是哪(nǎ)家公司,都不(bú)可(kě)能靠突击几个月就(jiù)能(néng)做出这样的大语言模型(xíng)。深(shēn)度学习、自然语(yǔ)言处理,需要多年的坚持和积累,没法速成。
“人类进入人工智能时代,IT技(jì)术的(de)技术栈发生了根(gēn)本性变化。过(guò)去基本分(fèn)为(wéi)三层:芯片层(céng),操作系(xì)统层和应用(yòng)层。现在可以分为(wéi)四(sì)层:芯片层、框架层、模型层和应(yīng)用(yòng)层。”他介绍说,“今天(tiān),百度是(shì)全球为数不多、在这四层进行全栈布局的人(rén)工智能公司,从高端芯片(piàn)昆仑芯,到飞桨深度(dù)学(xué)习框架,再到文心预训练(liàn)大模型,到搜(sōu)索、智(zhì)能(néng)云(yún)、自动驾驶、小度等(děng)应(yīng)用,各个层面(miàn)都有领先业界(jiè)的自研技术。”
文心一言(yán)位于模型层。2019年,百度推出(chū)了文心大模型ERNIE 1.0。目前,ERNIE 3.0每天(tiān)接(jiē)受(shòu)数十亿次用户的搜(sōu)索请求。这让文心(xīn)一(yī)言能够基于一个庞大的(de)、高效的数据池(chí),快速地学习(xí)和改进。
“大模型训(xùn)练堪称暴(bào)力美(měi)学,需(xū)要有大算力(lì)、大数据和(hé)大模型,每一次训练任务都耗资巨大。全栈布局的优势(shì)在于,可以(yǐ)在(zài)技术栈的四层架(jià)构(gòu)中,实现端(duān)到端优化,大幅提升(shēng)效率。尤其是,框架(jià)层和模型层(céng)之间,有很强的协同作用,可(kě)以帮助构建(jiàn)更高效(xiào)的(de)模型(xíng),并显著降低成本。事实上,超大(dà)规模模(mó)型(xíng)的训(xùn)练和推(tuī)理,给深度(dù)学(xué)习框(kuàng)架(jià)带来了很大考验。比如,为了(le)支持千亿参数模型(xíng)的高效分布式训练(liàn),百度飞(fēi)桨专门研发了 4D 混合(hé)并行技术。”李彦宏(hóng)介绍道。
“另(lìng)外,芯片(piàn)、框架、大模型和(hé)终端应用场景,可以形成一个高效的反(fǎn)馈(kuì)闭(bì)环,帮(bāng)助大模(mó)型不断去调优迭代,越做越好。更好的大模型,会让用户体验不(bú)断(duàn)升级。”
最后,李彦宏强调:“在全球范围内,在四层架构的每一(yī)层(céng)都(dōu)有领(lǐng)先产品的公(gōng)司(sī)几乎没有(yǒu),百度(dù)的优势(shì)非常独特,相信大家(jiā)会在(zài)后续文心的迭代速(sù)度上有明显感受(shòu)。”











案信息")
息举报中心")
络110")